Serwery GPU A100 do obliczeń
Serwery do obliczeń o wysokiej wydajności i sztucznej inteligencji.
Serwery GPU oferują wyższą wydajność i udostępniają nowe możliwości dla obciążeń HPC, analizy danych i sztucznej inteligencji w porównaniu z serwerami opartymi na CPU. Coraz szersze zastosowania procesorów graficznych wymusza różnorodność i elastyczność serwerów GPU. Poniższe informacje służą pomocą w doborze konfiguracji i ocenie korzyści jakie niosą one ze sobą dzięki zastosowaniu najnowszych technologii, które udostępnia firma NVIDIA.
GPU NVIDIA A100
Procesor graficzny NVIDIA A100 z rdzeniami tensorowymi zapewnia bezprecedensowe przyspieszenie w każdej skali zasilając najwydajniejsze na świecie elastyczne centra danych dla sztucznej inteligencji, analizy danych i obliczeń o wysokiej wydajności (HPC). Oparty na architekturze NVIDIA Ampere zapewnia nawet 20-krotnie wyższą wydajność w porównaniu z poprzednią generacją.

O to wybrane zalety procesora graficznego A100:
- Multi-Instance GPU (MIG) umożliwia każdemu procesorowi A100 uruchamianie siedmiu oddzielnych i izolowanych aplikacji lub sesji użytkownika, aby dynamicznie dostosowywać się do zmieniających się wymagań.
- Poprawiona wydajność obliczeń HPC do 9,7 TFLOPS podwójnej precyzji w obliczeniach zmiennoprzecinkowych (19,5 TFLOPS dla FP64 na rdzeniach tensorowych)
- Poprawiona wydajność akceleracji głębokiego uczenia do 3x~20x przy trenowaniu sieci neuronowych i 7x~20x dla wnioskowania (w porównaniu z GPU poprzedniej generacji Tesla V100)
- Większa i szybsza pamięć GPU to 80 GB o przepustowości sięgającej 2 TB/s
- Szybsza wymiana danych pomiędzy GPU dzięki NVLink trzeciej generacji zapewniającemu 10x~20x szybsze transfery niż PCI-Express
Podobnie jak w przypadku poprzednich procesorów graficznych dla centrów danych firma NVIDIA udostępnia GPU A100 w dwóch wykonaniach:
- Moduł SXM z NVLink — o zwartej budowie, zaprojektowany z myślą o szybkości i wydajności
- Karta PCI-Express — standardowa konstrukcja zgodna z poprzednimi wersjami
Najczęściej spotykane systemy oparte o GPU A100 sprowadzają się do czterech konfiguracji. W dwóch z nich GPU są połączone ze sobą za pomocą złączy NVLink, które są najlepsze dla dużych instalacji HPC/AI w przypadku gdy wszystkie procesorami graficzne pracują razem w tej samej aplikacji. Pozostałe dwa systemy tworzą konfiguracje bardziej uniwersalne z GPU w wykonaniu karty PCIe.
Serwery GPU A100 z komunikacją poprzez NVLink
Systemy połączone przez NVLink są idealne dla aplikacji, które działają jednocześnie na kilku procesorach graficznych (takich jak wymagające aplikacje HPC i większość aplikacji do głębokiego uczenia – TensorFlow, PyTorch itp.). Łączność NVLink pozwala procesorom GPU koordynować i udostępniać dane tak wydajnie, jak to tylko możliwe dzięki bezpośredniemu połączeniu GPU szyną danych o wielokrotnie większej przepustowości niż szyna PCIe. Architektura GPU Ampere firmy NVIDIA podwoiła przepustowość NVLink. W porównaniu z tradycyjnym PCI-Express 3.0, NVLink jest dwadzieścia razy szybszy.
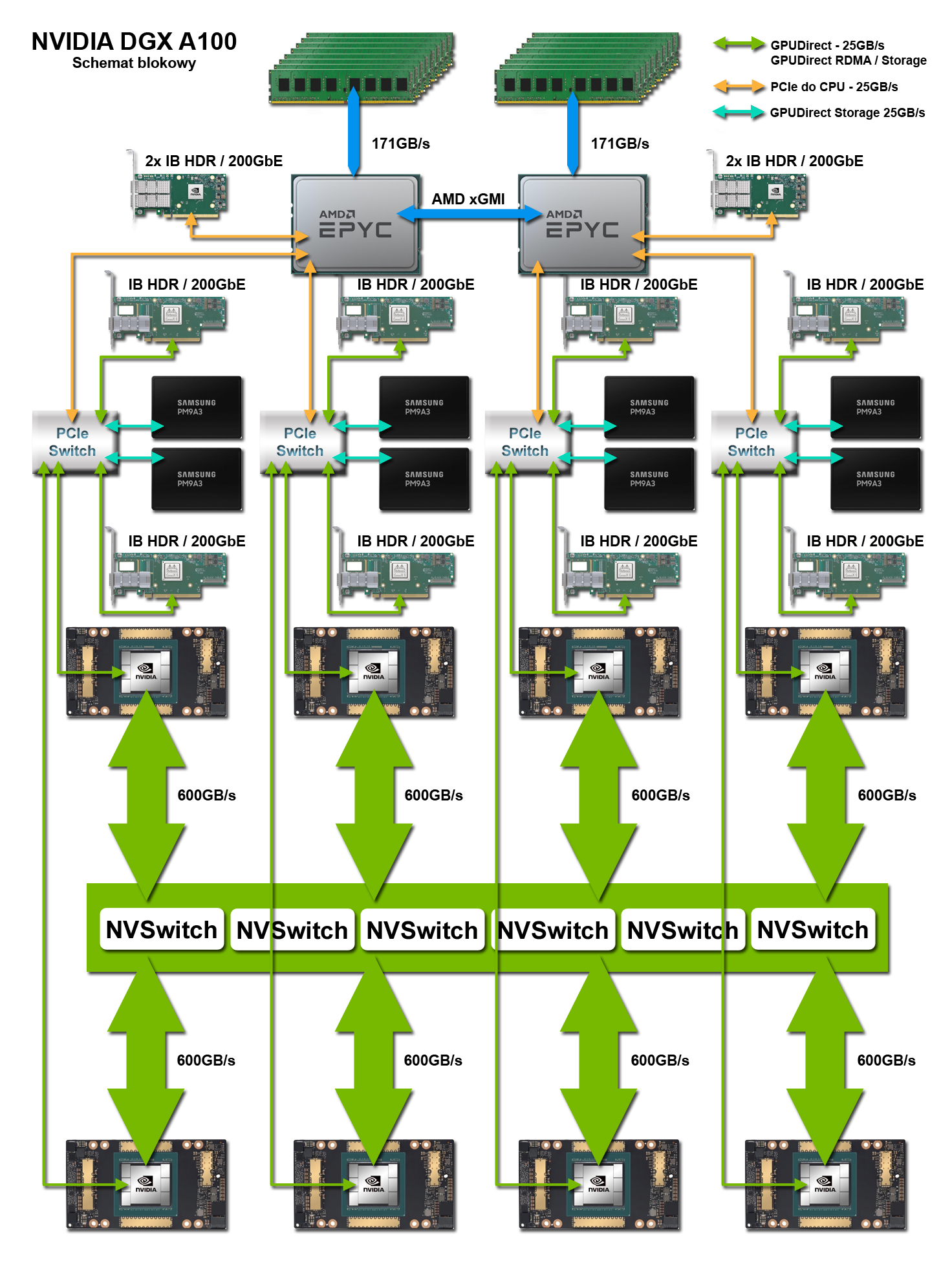
NVIDIA DGX A100 z przełącznikami NVSwitch
DGX A100 to zoptymalizowana platforma stworzona przez firmę NVIDIA specjalnie dla zastosowań HPC i AI. DGX, w połączeniu z wysoce zoptymalizowanymi kontenerami z oprogramowaniem, zapewnia najlepszą wydajność podczas trenowania sieci neuronowych i uruchamiania wnioskowania na skalę produkcyjną. NVIDIA DGX A100 zapewnia najszybszą wydajność GPU na świecie dzięki pełnemu wykorzystaniu technologii GPUDirect. 6 przełączników NVSwitch powala na wymianę danych pomiędzy GPU z transferem rzędu 600 GB/s (12 połączeń o dwukierunkowej przepustowości 50 GB/s dla każdego GPU). Dzięki nim system oddaje do dyspozycji łączną pojemność 640GB pamięci GPU. Przy większej ilości danych system korzysta z lokalnych napędów NVMe, które dzięki wykorzystaniu technologii GPUDirect Storage traktowane są jako podręczny cache o pojemności 30 TB. Bardzo duże zbiory wymagają zewnętrznej pamięci masowej, do której dostęp zapewnia bezpośrednie połączenie każdego GPU z kartą sieciową o przepustowości 200 Gb/s. Te połączenia służą jednocześnie do wymiany danych z nodami w klastrze GPU.
DGX A100 jest idealnym rozwiązaniem dla tych, którzy potrzebują maksymalnej wydajności z wykorzystaniem NVLink i pragną korzystać zarówno z eksperckiej wiedzy firmy NVIDIA, jak i wstępnie zoptymalizowanych przez firmę pakietów oprogramowania.
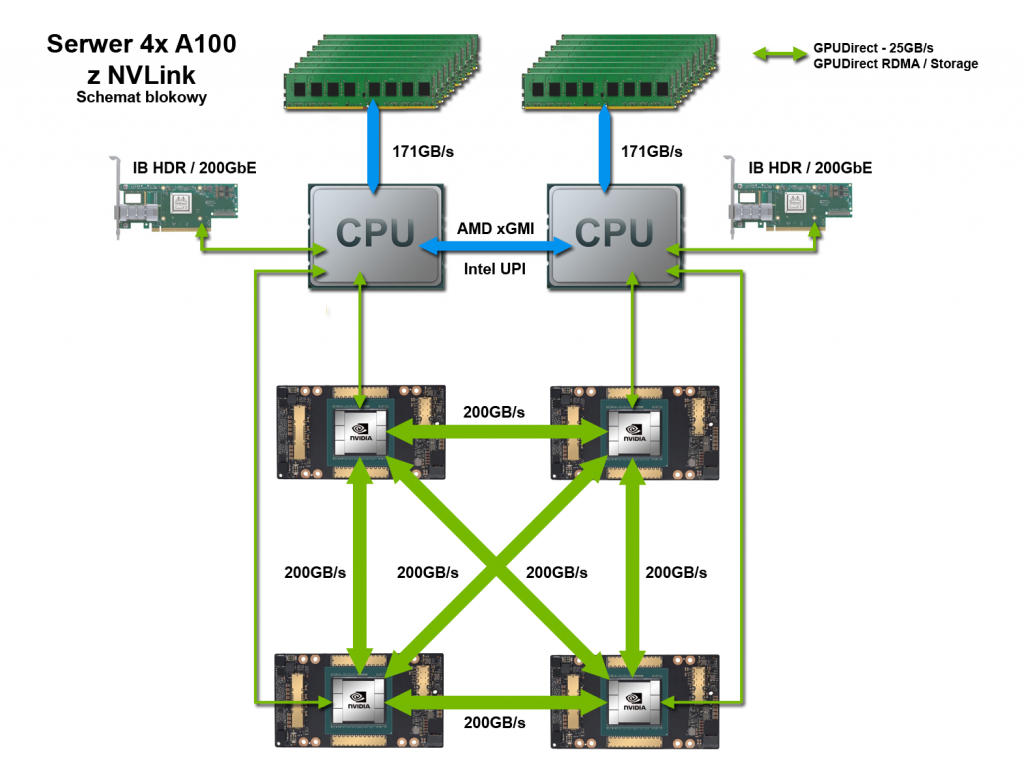
Serwer GPU z 4 GPU A100 i NVLink
Serwer GPU A100 z NVLink umożliwia przetwarzanie o dużej gęstości (obudowa rack 2U) i wykorzystuje najnowsze technologie HPC (high-performance computing) i sieci komputerowej. Serwer może pracować samodzielnie lub jako część klastra z pełną przepustowością 2x 200 Gb/s pomiędzy każdym z węzłów. W ramach jednej nody procesory graficzne wykorzystują połączenia NVLink o przepustowości 200 GB/s do przesyłania danych pomiędzy każdą z par GPU.
Jest to rozwiązanie dla tych z użytkowników, którzy potrzebują zbalansowanej mocy obliczeniowej CPU/GPU z wykorzystaniem NVLink, ale posiadają własny stos programowy.
UWAGA: Serwer można skonfigurować na zamówienie zgodnie z dokładną specyfikacją użytkownika.
Serwery GPU A100 z komunikacją poprzez szynę PCI-Express
Procesory graficzne NVIDIA A100 są również dostępne jako standardowe karty PCIe. Jest to zwykle pożądane w przypadku wdrożeń bardziej ogólnego przeznaczenia, w przypadkach, gdy aplikacje użytkownika nie są mocno ukierunkowane na akcelerację GPU lub w przypadkach, gdy każda aplikacja/użytkownik nie będzie potrzebował więcej niż jednego GPU. Te serwery z GPU A100 są bardzo ekonomiczne, z możliwością montażu od jednego do dziesięciu procesorów GPU w serwerze.
Na obsługiwanych platformach karty A100 PCIe można łączyć w pary za pomocą potrójnego mostka NVLink o całkowitej przepustowości 600GB/s. Dzięki temu na przykład aplikacje, które nie są zoptymalizowane pod kątem większej liczby procesorów graficznych, mogą korzystać z podwójnej mocy obliczeniowej (rdzeni CUDA) jak i podwójnej ilości pamięci (160GB) jako jednego GPU.
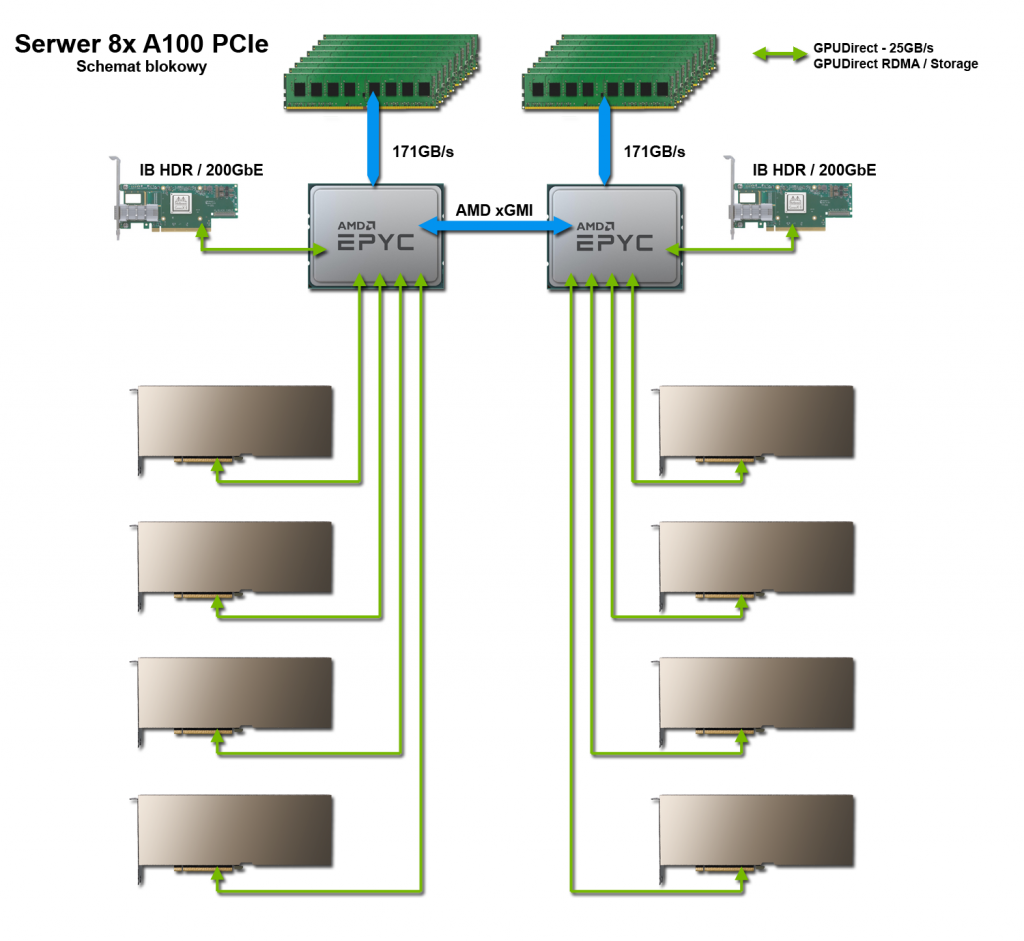
Dwuprocesorowy serwer GPU z 8 GPU NVIDIA A100
Obudowa 4U i dwa CPU w serwerze zapewniają niezwykłą elastyczność poprzez obsługę wielu dodatkowych urządzeń oprócz procesorów graficznych A100. Wiele kieszeni na szybkie napędy NVMe, czy dysponujące dużą pojemnością i przystępne cenowo napędy HDD, dają możliwość swobodnego kształtowania lokalnej pamięci masowej. Procesory AMD EPYC są w stanie obsłużyć dużą liczbę szybkich urządzeń PCIe, czy to pamięci masowej, kart sieciowych czy obliczeniowych.
To rozwiązanie jest idealne dla klastrów, od których oczekuje się wykonywania wielu zadań wykorzystujących jedno lub dwa GPU, a także klastrów, które wymagają dostosowania konfiguracji w celu uzyskania najlepszej wydajności konkretnej aplikacji, np. symulacji inżynierskiej.
UWAGA: Serwer można skonfigurować na zamówienie zgodnie z dokładną specyfikacją użytkownika.
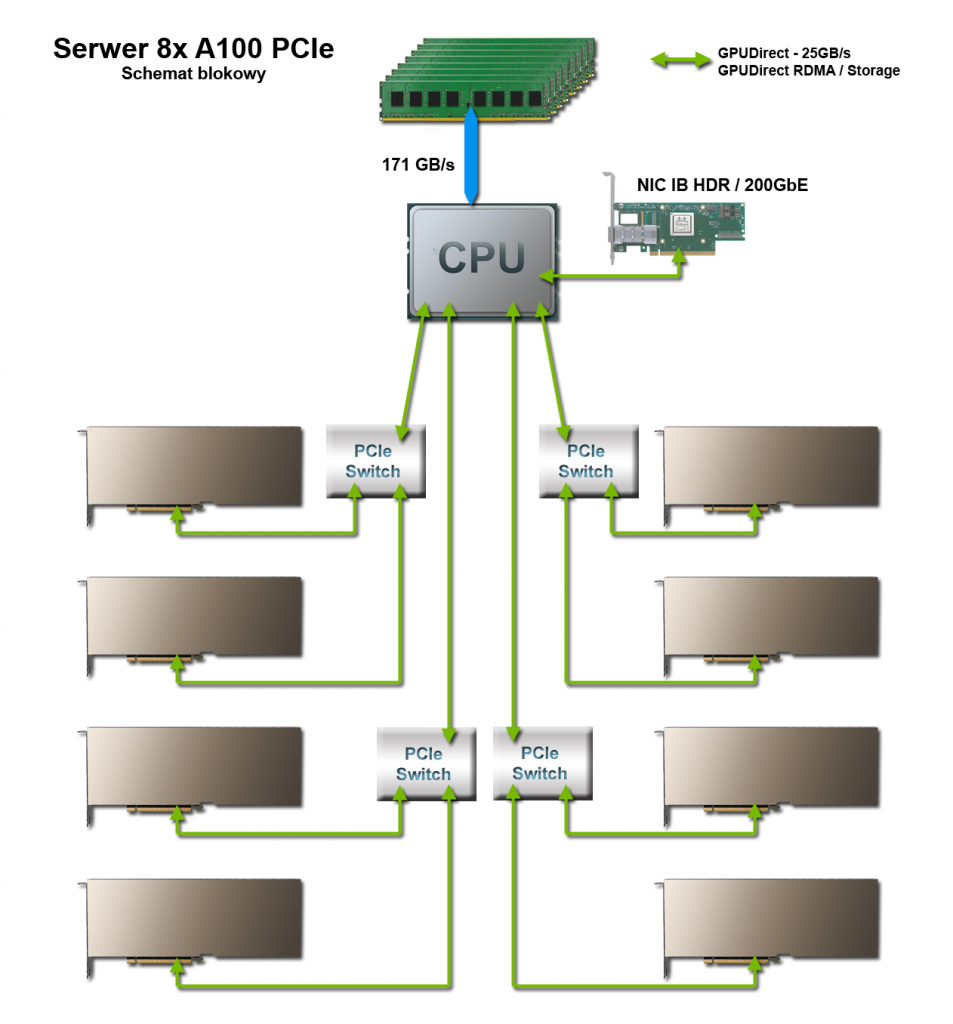
Jednoprocesorowy serwer GPU z 8 GPU NVIDIA A100
Serwer może obsługiwać do 8 kart podwójnej grubości w obudowie rack 2U, dzięki czemu zapewnia wiodące na świecie HPC o dużej gęstości upakowania. Jest to serwer do aplikacji, które są dobrze zoptymalizowane pod kątem akceleracji GPU i wymagają stosunkowo niewielkiej liczby rdzeni procesora. Taka konfiguracja pozwala użytkownikom końcowym alokować swój budżet najbardziej tam, gdzie ma to największe znaczenie dla największego przyspieszenia wydajności obliczeniowej: w dodatkowych procesorach graficznych.
Idealny do zastosowań HPC, takich jak analityka w czasie rzeczywistym, programy do symulacji i modelowania naukowego, inżynieria, wizualizacja i renderowanie, eksploracja danych i wiele innych.
UWAGA: Serwer można skonfigurować na zamówienie zgodnie z dokładną specyfikacją użytkownika.
